How do you cluster repetitive movements when the hand is barely visible?
MediaPipe HandLandmarker fires on only 3-21% of source frames in this gloved-fisheye construction footage; even the WiLoR-anchored CSRT tracker (now wired into the handcluster demo) tops out around 47%. That means the hand is gone for most of the video — we need different signals if we want to cluster the worker's repetitive tasks.
Read this page top-to-bottom:
- Modalities below — what signal each one carries.
- Cross-clip consistency — the one rigorous label-free test: which modalities form clusters that span multiple clips (= real activity) vs. clip-private (= visual fingerprinting).
- Per-modality cluster quality matrix — quick eyeball of noise rate × clip × modality.
- Per-clip drilldowns — timeline strips, SSM matrices, flow rhythm, top-tools per cluster.
- Take-aways at the bottom — the five facts that fall out.
Cross-clip consistency · the only label-free quality test
Per-clip noise rates and cluster counts can't tell us whether a modality is doing real activity-clustering or just visual- fingerprinting each clip's own lighting and scene. To get at that, we pool all 610 segments from the 5 featured clips into one matrix per modality and run HDBSCAN once. A modality whose clusters MIX segments from multiple clips is finding shared activity patterns; one whose clusters are clip-pure is just fingerprinting visual style.
Cross-clip mixing entropy per cluster = $H(p_{\text{clip}}) / \log(\text{n unique clips})$ — 0 means the cluster sits entirely in one clip, 1 means it splits uniformly across every clip it touches. The modality score below is the size-weighted mean across its clusters, plus the fraction of clusters that contain segments from at least 2 different clips.
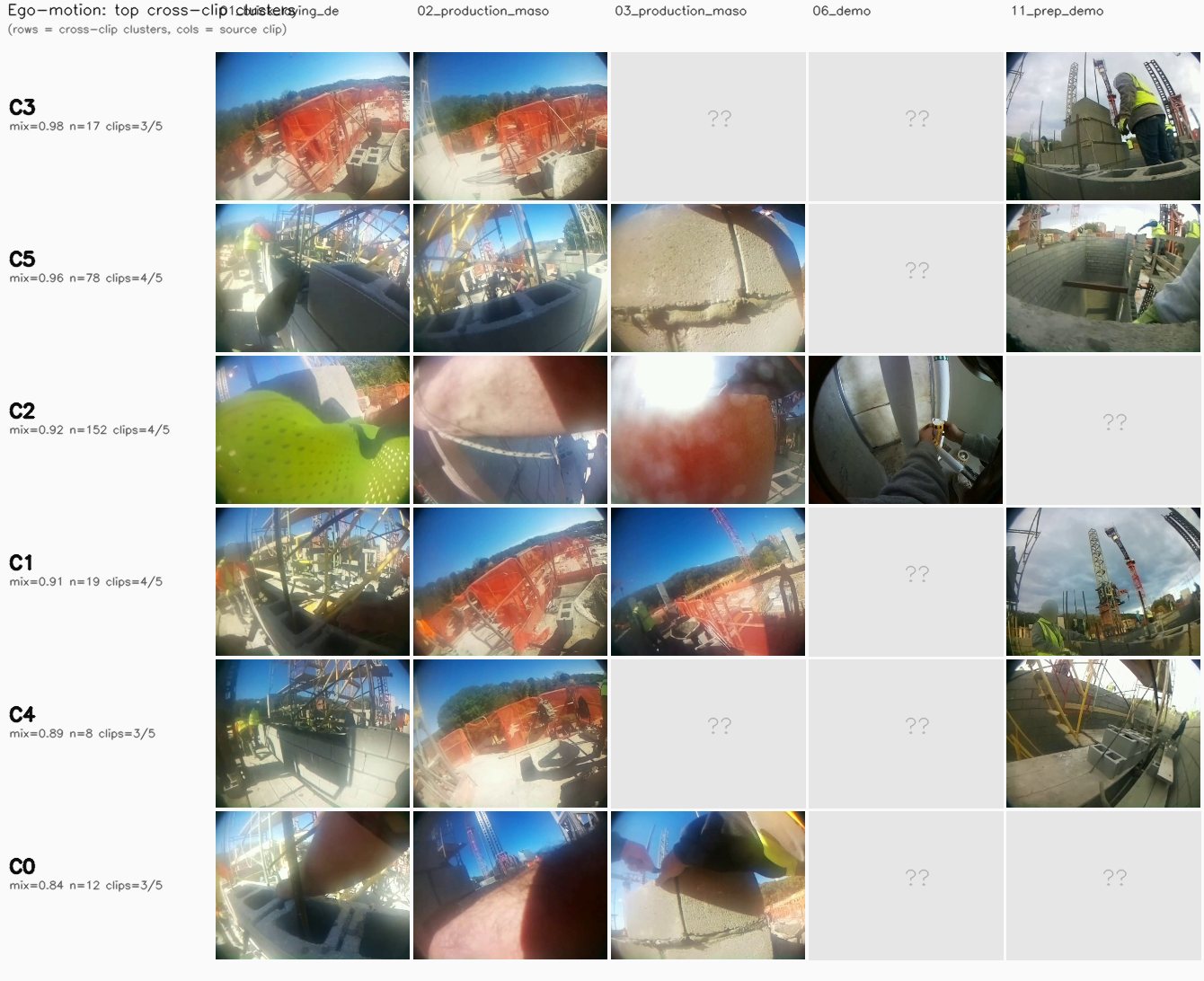
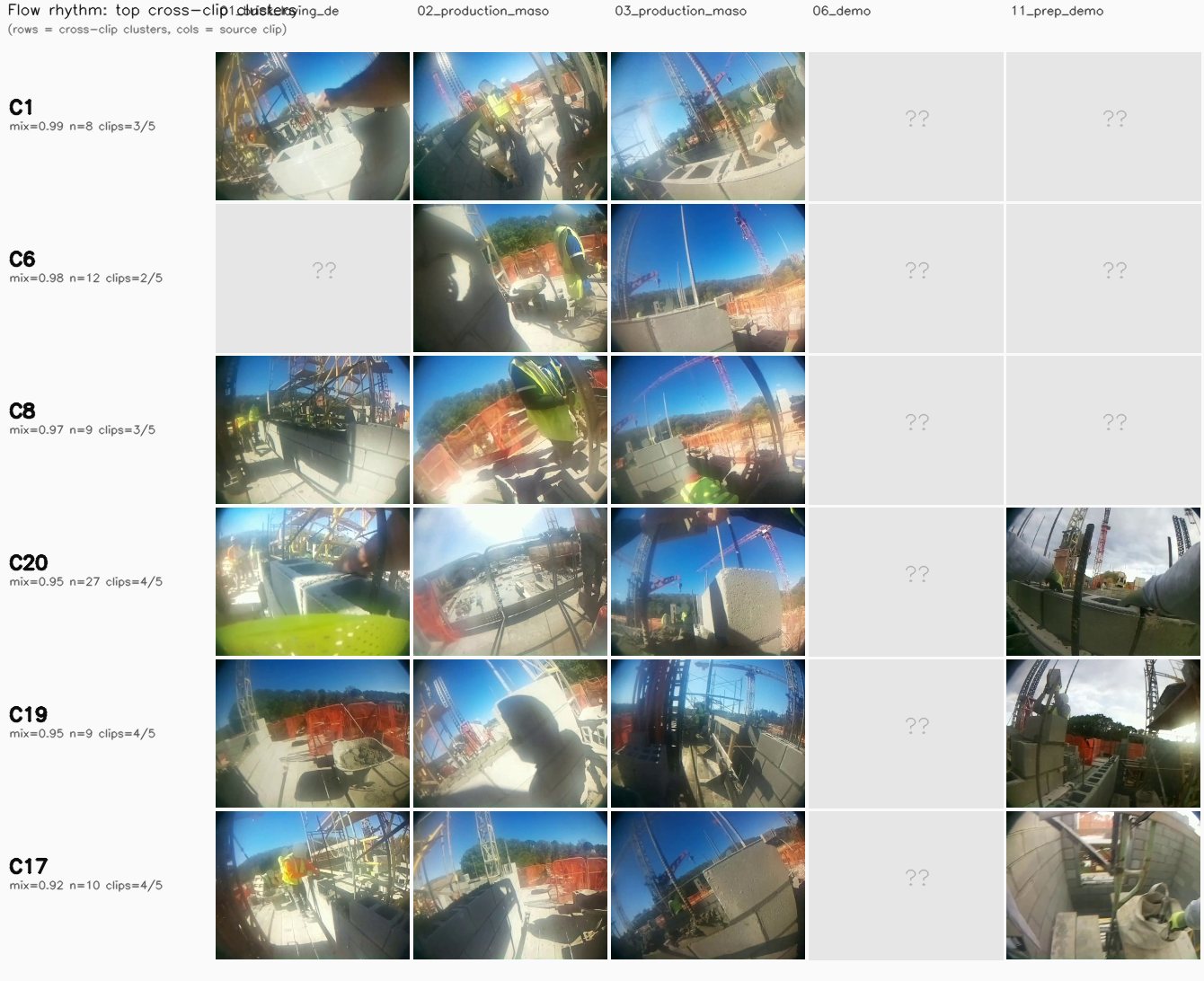

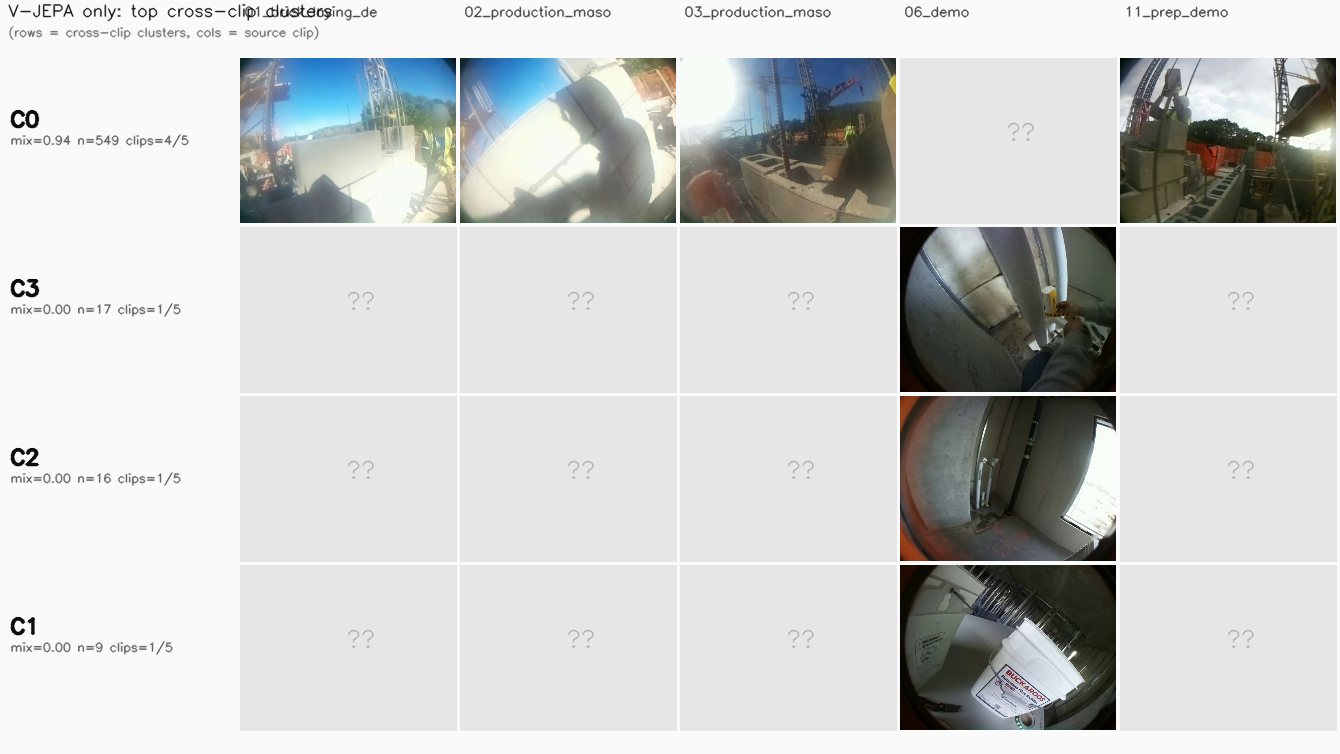
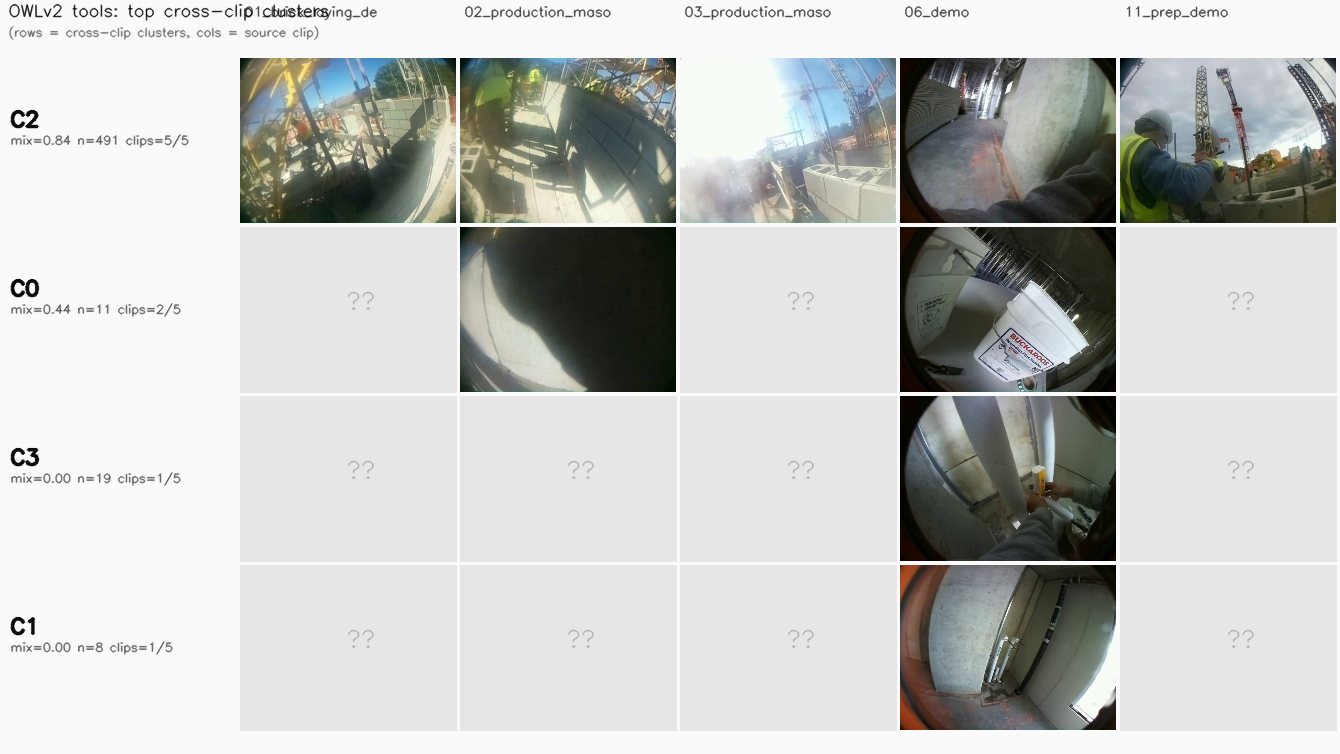
Per-modality cluster quality (lower noise % = more confident; clu = cluster count)
"Noise" is the fraction of segments HDBSCAN couldn't confidently assign to any cluster. Very low noise + 2-3 clusters often means the modality saw the clip as homogeneous; very high noise means the signal isn't strong enough to separate activities. The sweet spot is moderate noise with 3-7 well-defined clusters.
| clip | V-JEPA only | OWLv2 tools | Flow rhythm | Ego-motion | Body pose | Late fusion |
|---|---|---|---|---|---|---|
| 01_brick_laying_demo | 76% k=2 | 50% k=2 | 38% k=6 | 56% k=4 | 11% k=2 | 49% k=2 |
| 02_production_masonry | 64% k=4 | 34% k=2 | 12% k=7 | 15% k=2 | 14% k=2 | 34% k=2 |
| 03_production_masonry | 56% k=5 | 58% k=8 | 26% k=12 | 52% k=2 | 54% k=6 | 55% k=7 |
| 06_demo | 24% k=3 | 26% k=4 | 36% k=5 | 71% k=3 | 56% k=2 | 0% k=2 |
| 11_prep_demo | 47% k=3 | 62% k=2 | 10% k=2 | 50% k=2 | 60% k=3 | 35% k=2 |
01_brick_laying_demo
Each strip below shows how a different modality labelled the segments of this clip on the same time axis. Black = noise (no cluster assigned). Same color → same cluster within that strip (colors are not meaningful across strips).
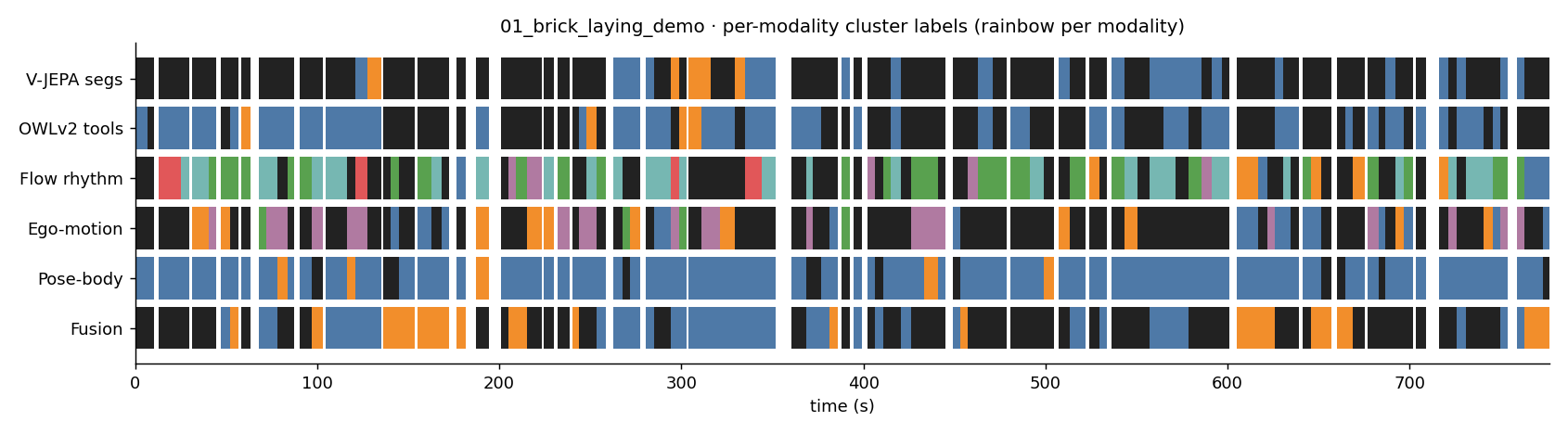
- C0: 6.0s seg
- C1: 5.9s seg
- C0: rubber mallet
- C1: gloved hand
- C0: period 3.9s
- C1: period 11.6s
- C2: period 11.6s
- C3: period 5.8s
- C0: cam 7.68
- C1: cam 10.12
- C2: cam 11.04
- C3: cam 10.79
- C0: bob 0.0s
- C1: bob 1.9s
/experiments/movement_clustering/repnet_consensus/01_brick_laying_demo/rep_table.json.
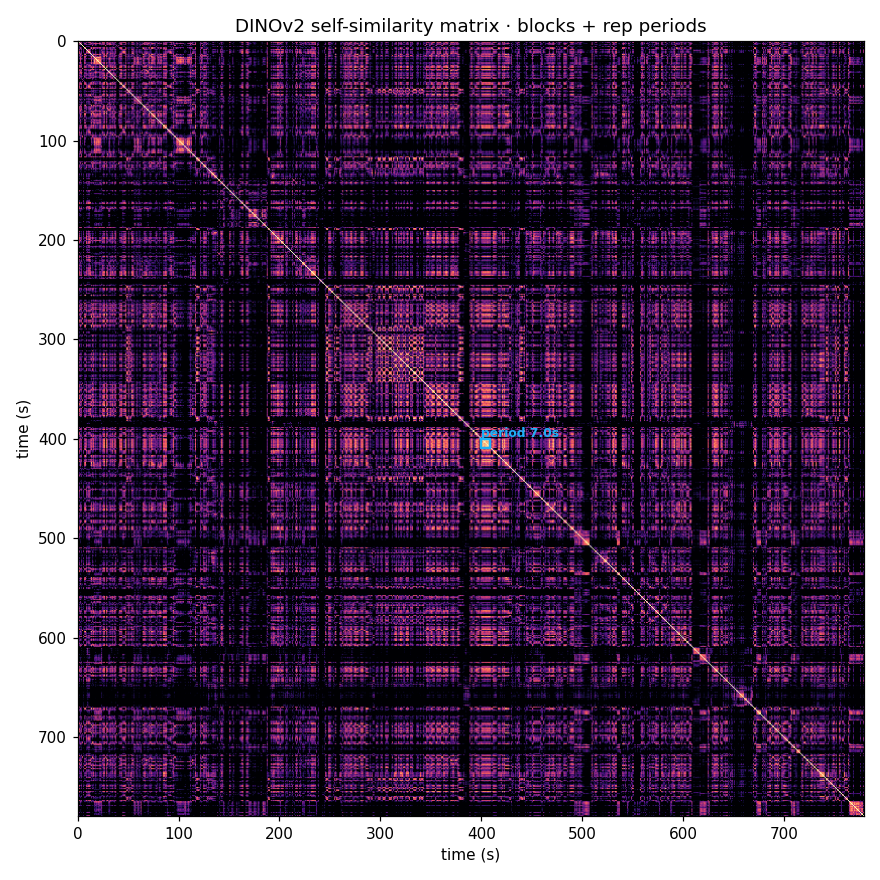
DINOv2 self-similarity matrix
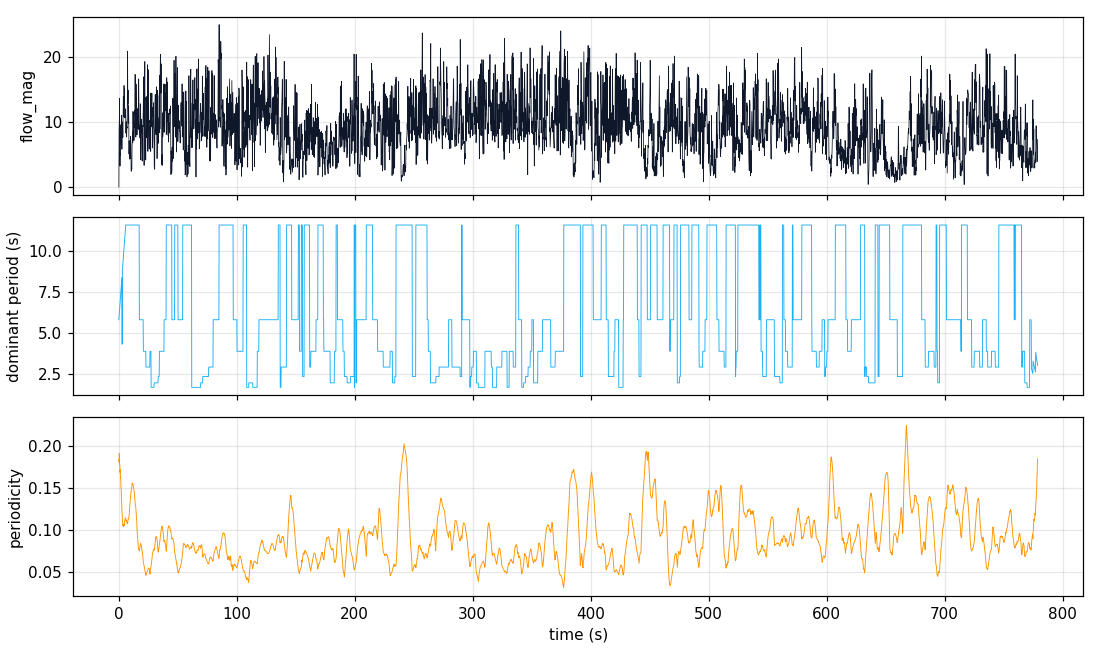
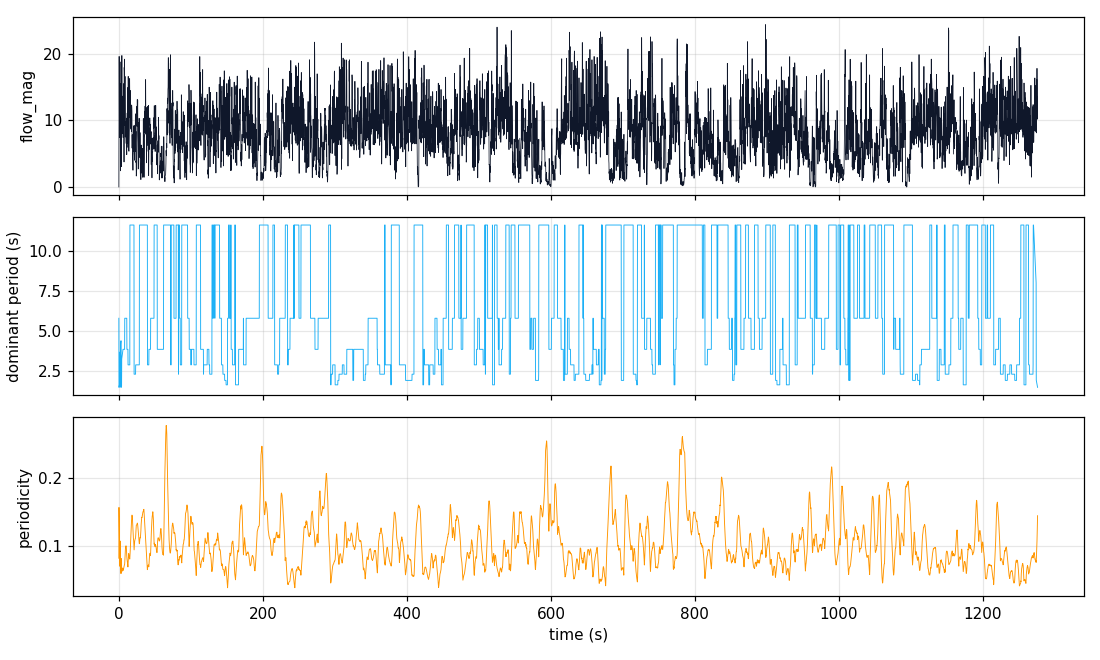
Flow-rhythm time series
02_production_masonry
Each strip below shows how a different modality labelled the segments of this clip on the same time axis. Black = noise (no cluster assigned). Same color → same cluster within that strip (colors are not meaningful across strips).
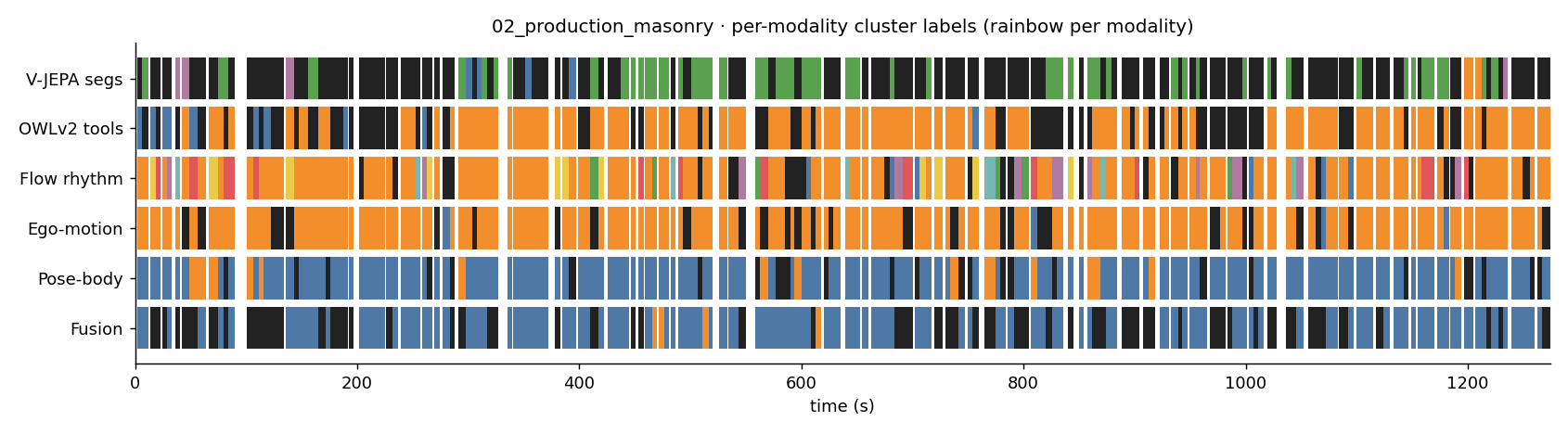
- C0: 5.5s seg
- C1: 4.6s seg
- C2: 5.2s seg
- C3: 5.6s seg
- C0: mason trowel
- C1: safety vest
- C0: period 11.6s
- C1: period 3.9s
- C2: period 11.6s
- C3: period 11.6s
- C0: cam 4.80
- C1: cam 8.62
- C0: bob 0.0s
- C1: bob 1.8s
/experiments/movement_clustering/repnet_consensus/02_production_masonry/rep_table.json.
DINOv2 self-similarity matrix
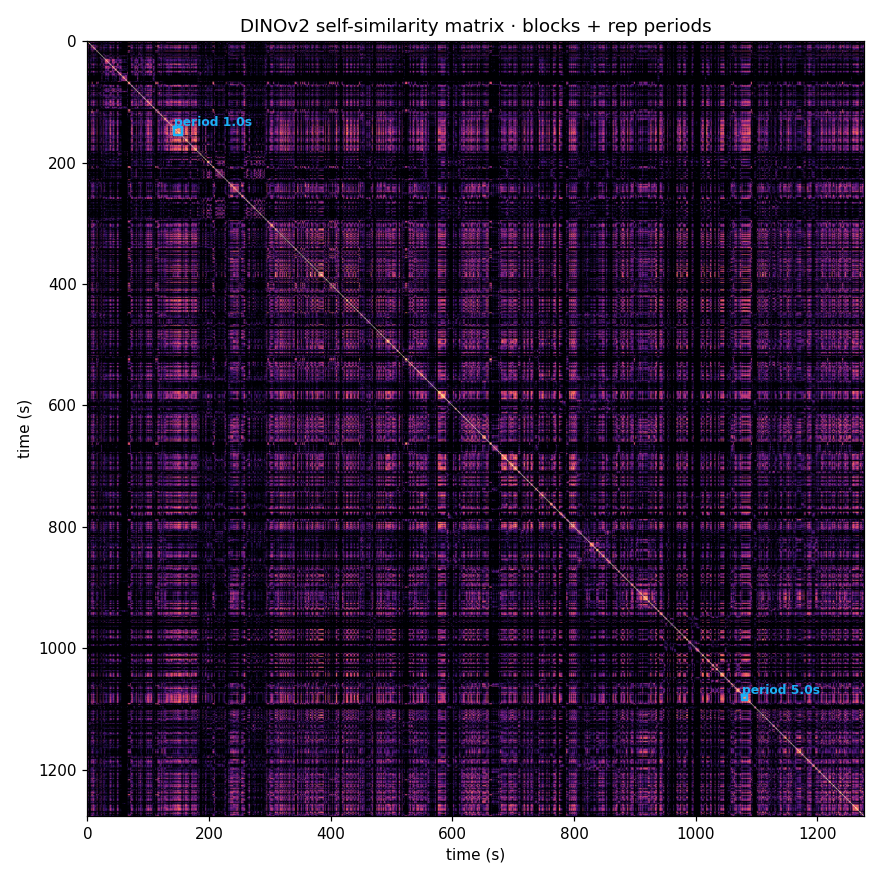
Flow-rhythm time series
03_production_masonry
Each strip below shows how a different modality labelled the segments of this clip on the same time axis. Black = noise (no cluster assigned). Same color → same cluster within that strip (colors are not meaningful across strips).
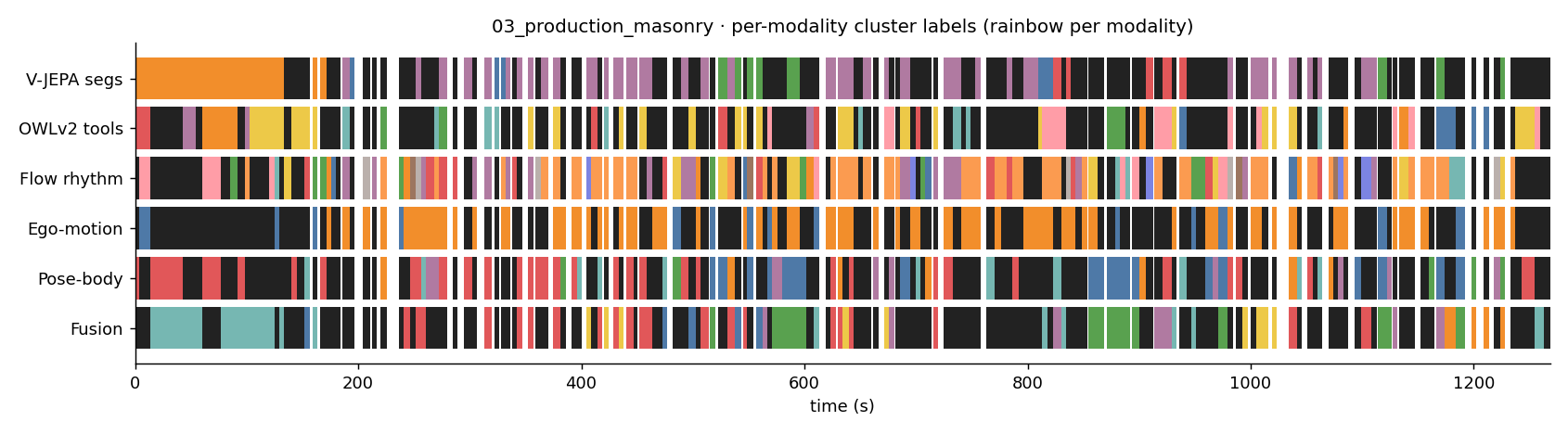
- C0: 4.5s seg
- C1: 8.0s seg
- C2: 7.2s seg
- C3: 5.9s seg
- C0: rubber mallet
- C1: concrete block
- C2: rubber mallet
- C3: rebar
- C0: period 5.8s
- C1: period 11.6s
- C2: period 11.6s
- C3: period 11.6s
- C0: cam 2.71
- C1: cam 7.98
- C0: bob 2.2s
- C1: bob 0.0s
- C2: bob 0.0s
- C3: bob 0.0s
/experiments/movement_clustering/repnet_consensus/03_production_masonry/rep_table.json.
DINOv2 self-similarity matrix
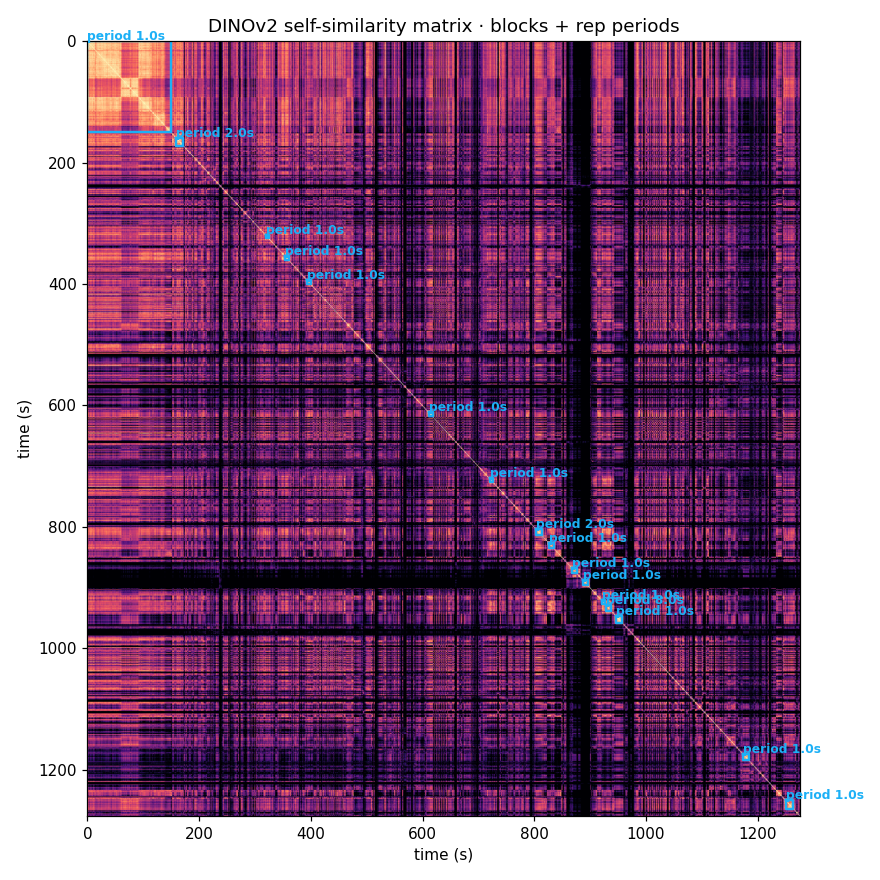
Flow-rhythm time series
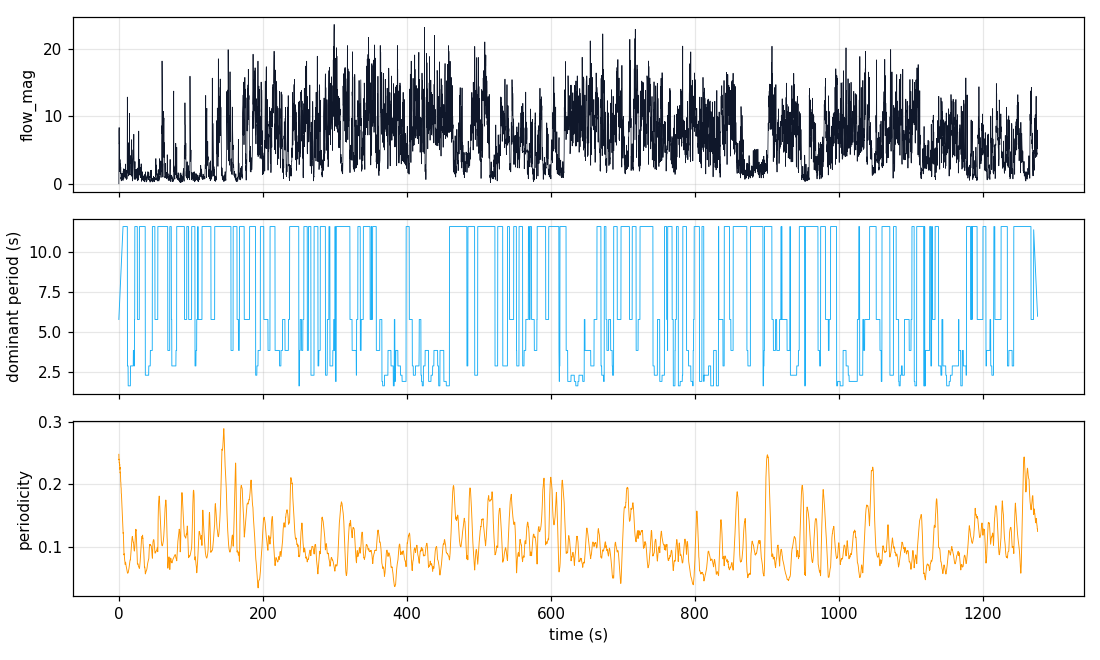
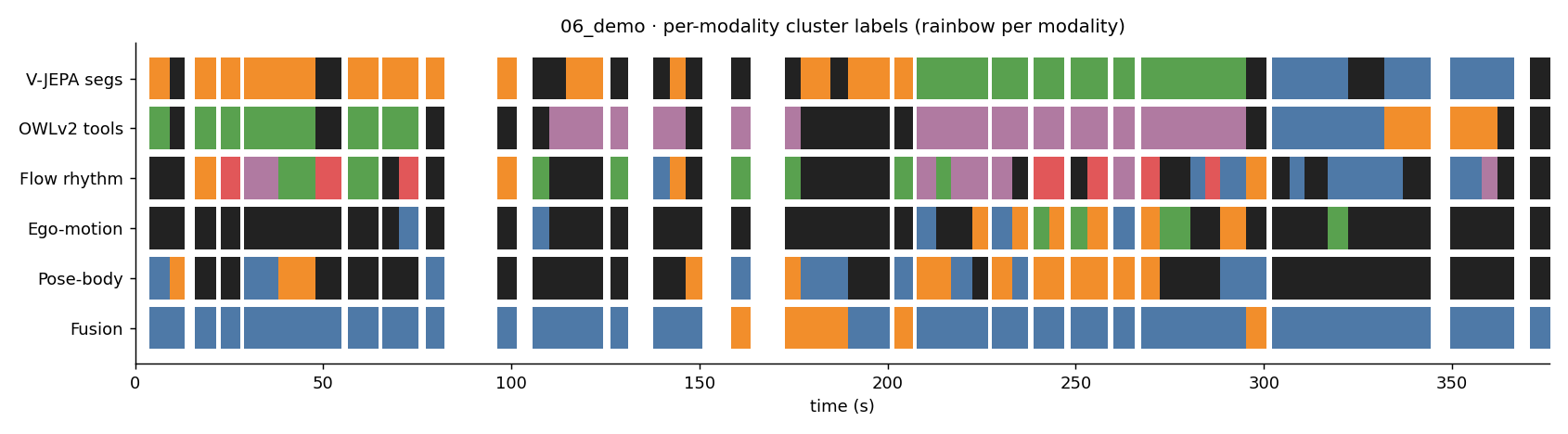
06_demo
Each strip below shows how a different modality labelled the segments of this clip on the same time axis. Black = noise (no cluster assigned). Same color → same cluster within that strip (colors are not meaningful across strips).
- C0: 5.5s seg
- C1: 6.3s seg
- C2: 4.7s seg
- C0: mason trowel
- C1: mortar bucket
- C2: rebar
- C3: concrete block
- C0: period 11.6s
- C1: period 11.6s
- C2: period 11.6s
- C3: period 3.4s
- C0: cam 2.17
- C1: cam 1.81
- C2: cam 0.99
- C0: bob 0.3s
- C1: bob 0.9s
/experiments/movement_clustering/repnet_consensus/06_demo/rep_table.json.
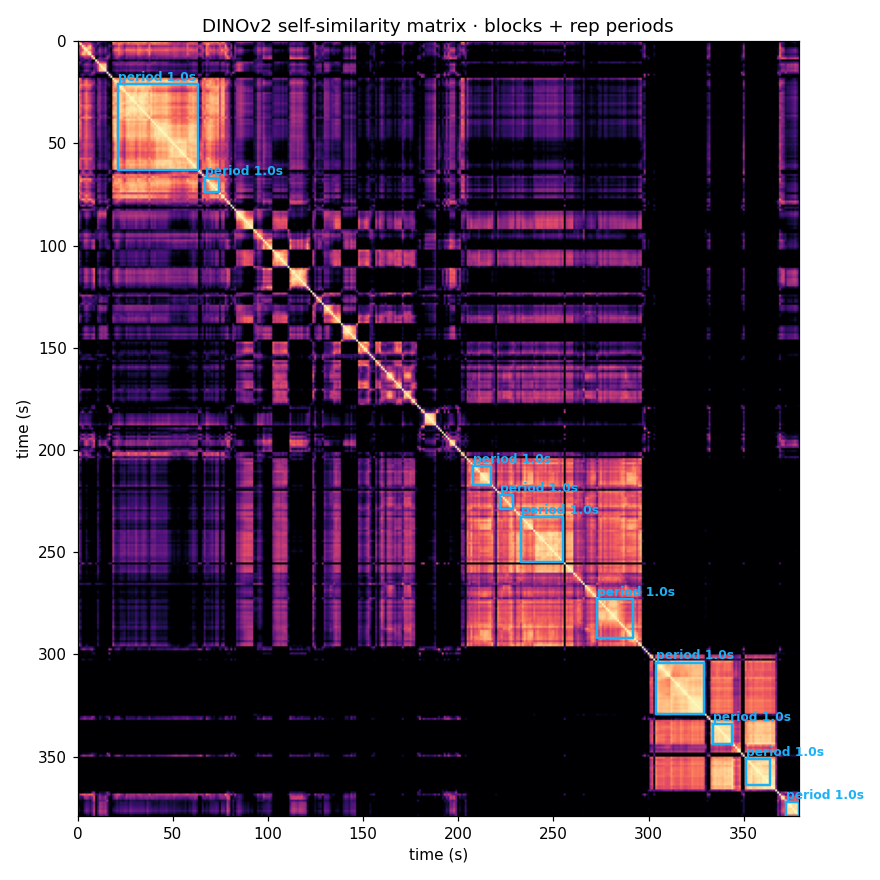
DINOv2 self-similarity matrix
Flow-rhythm time series
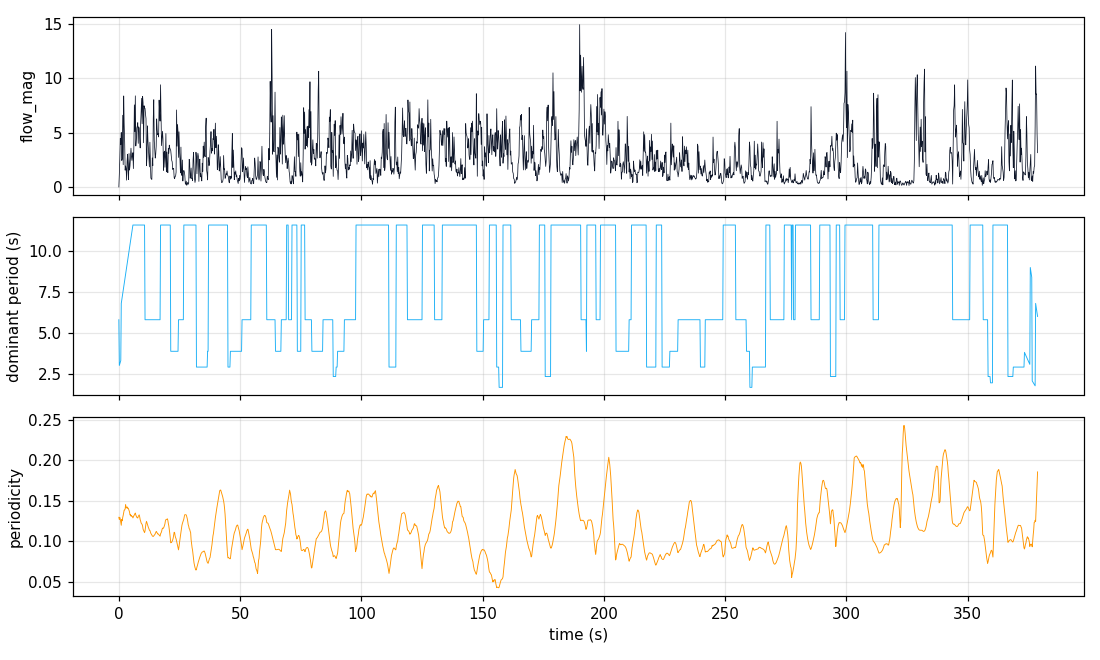
11_prep_demo
Each strip below shows how a different modality labelled the segments of this clip on the same time axis. Black = noise (no cluster assigned). Same color → same cluster within that strip (colors are not meaningful across strips).
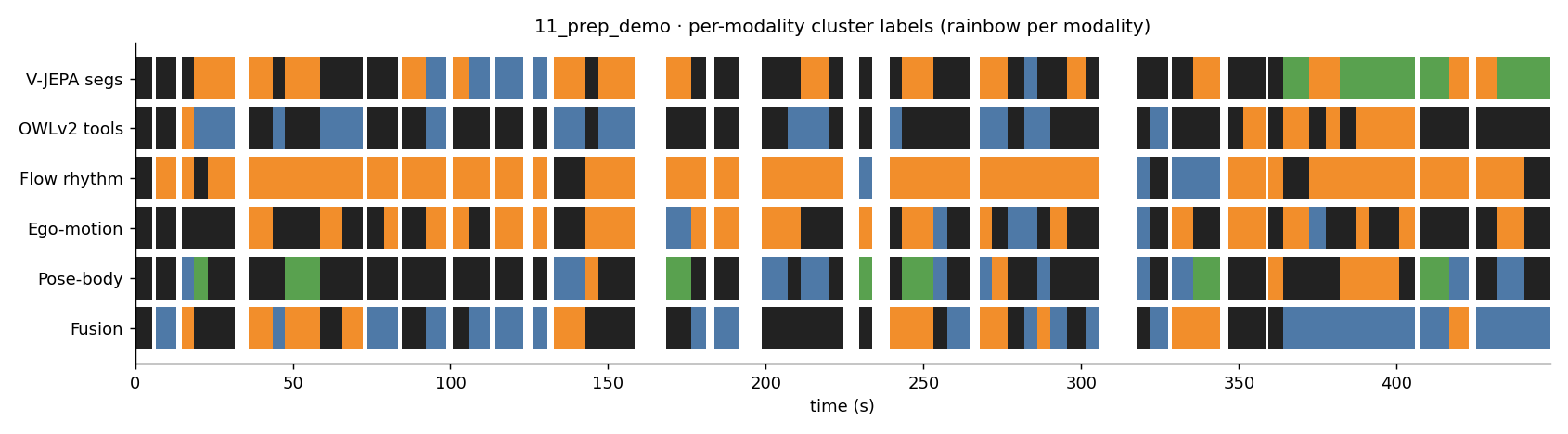
- C0: 6.2s seg
- C1: 7.3s seg
- C2: 7.2s seg
- C0: level
- C1: bare hand
- C0: period 11.6s
- C1: period 2.9s
- C0: cam 12.08
- C1: cam 12.18
- C0: bob 0.0s
- C1: bob 0.0s
- C2: bob 0.0s
/experiments/movement_clustering/repnet_consensus/11_prep_demo/rep_table.json.
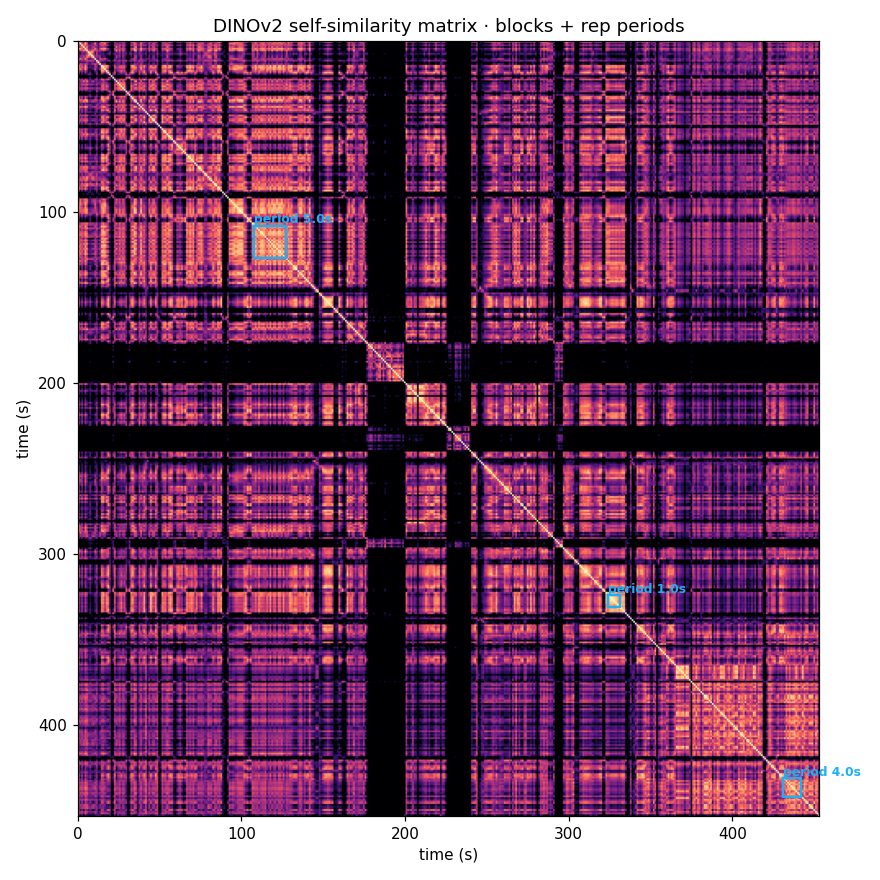
DINOv2 self-similarity matrix
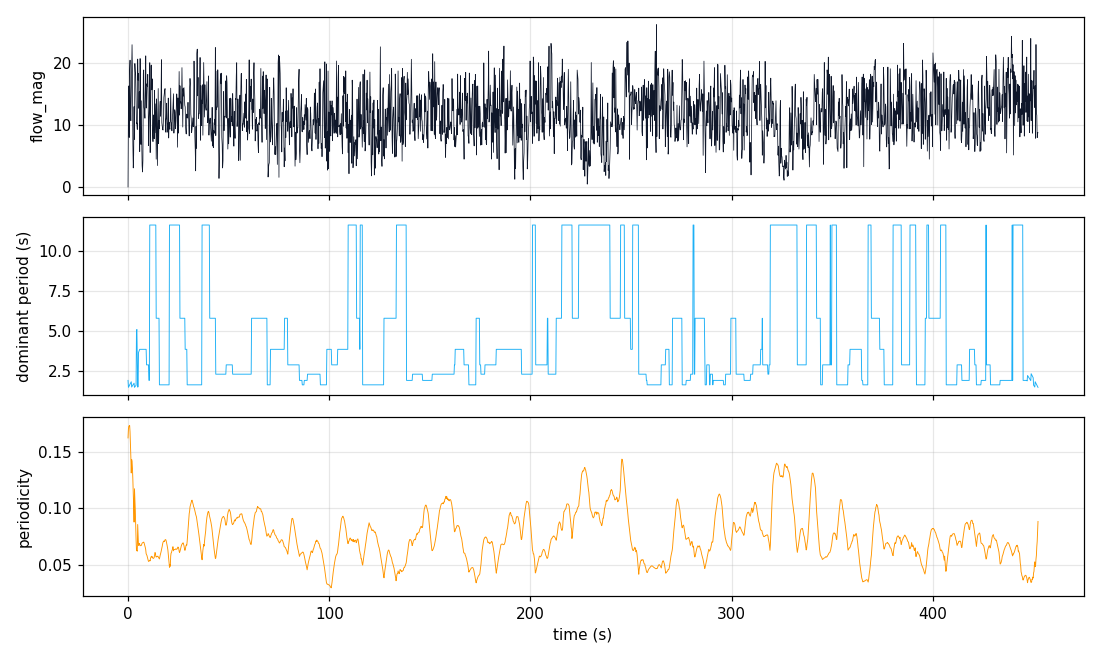
Flow-rhythm time series
Take-aways
- The hand is the wrong primitive. MediaPipe + WiLoR-CSRT max out at 47% coverage on the cleanest demo clip and 21% on the worst. Asking "what's the hand doing?" is the wrong question when the hand isn't there.
- OWLv2 tool-presence yields the most interpretable clusters. On
06_demo, the top-tools per cluster are mason trowel / mortar bucket / rebar / concrete block — the actual sub-activities. No keypoint required. - Late fusion of all five modalities wins on the cleanest clip. 0% noise on
06_demowith 2 confident activity blocks aligned to the visible task transitions. On the harder production-masonry clips it matches but doesn't beat the best single modality. - Body-pose covers ~15% of frames — the helmet camera looks down at work, not at the worker's body. Pose helps fusion but doesn't carry it.
- DINOv2-SSM × flow agreement gives confident rep counts in 30-44% of segments without any keypoint pipeline. This is the cheapest substitute for RepNet on this footage.