HandClust
1 · The problem
The data is just under five hours of helmet-cam masonry footage spread across 14 clips. Filenames hint at a coarse phase — production, prep, transit, downtime — but nothing in the video itself is labelled. The goal is to discover the activities that actually repeat across the footage and produce a per-clip timeline showing which activity is happening at each moment.
The obvious first idea — track the worker's hands frame by frame — falls apart on this footage. Workers wear gloves, the lens is wide-angle, and hands constantly leave the field of view. An off-the-shelf hand tracker (MediaPipe [3]) only finds a hand in 0.5–12.5 % of frames depending on the clip. Anything that needs hand keypoints is dead on arrival, so the design treats hand pose as a weak hint and leans on visual scene cues instead.
2 · How it works, in plain words
The pipeline runs four stages over each clip. Each stage is unsupervised — no labels go in.
- Sample frames at a fixed rate. Each clip is decoded at 5 frames per second. For every sampled frame the system records three things: a feature vector from a strong image model (DINOv2 [1]) that captures the scene, an optical-flow summary that captures how things are moving, and any hand keypoints the tracker happened to find.
- Cut the clip into short segments. Three different segment detectors look for "something just changed" — one watches motion, one watches scene appearance, one watches statistical change-points — and their proposals are averaged into a single set of segment boundaries. Using three detectors with different blind spots is steadier than relying on any one.
- Describe each segment. Every segment gets a video-level embedding from V-JEPA-2 [2] (a self-supervised video model trained for physical-world understanding) plus the average of the per-frame scene and motion features.
- Group segments by similarity. The three feature types are compared and combined so that confident signals can outweigh ambiguous ones. Segments that the combination judges similar end up in the same cluster — these are the discovered activities. A vision-language model (Gemini [5]) then writes a short label for each cluster ("scooping mortar", "climbing scaffold", and so on).
3 · Results
The only ground truth available is the coarse phase label baked into each clip's filename, so that's what the evaluation tests against. Two questions: do the discovered clusters line up with the phase label, and does using all three feature types together actually beat using any one?
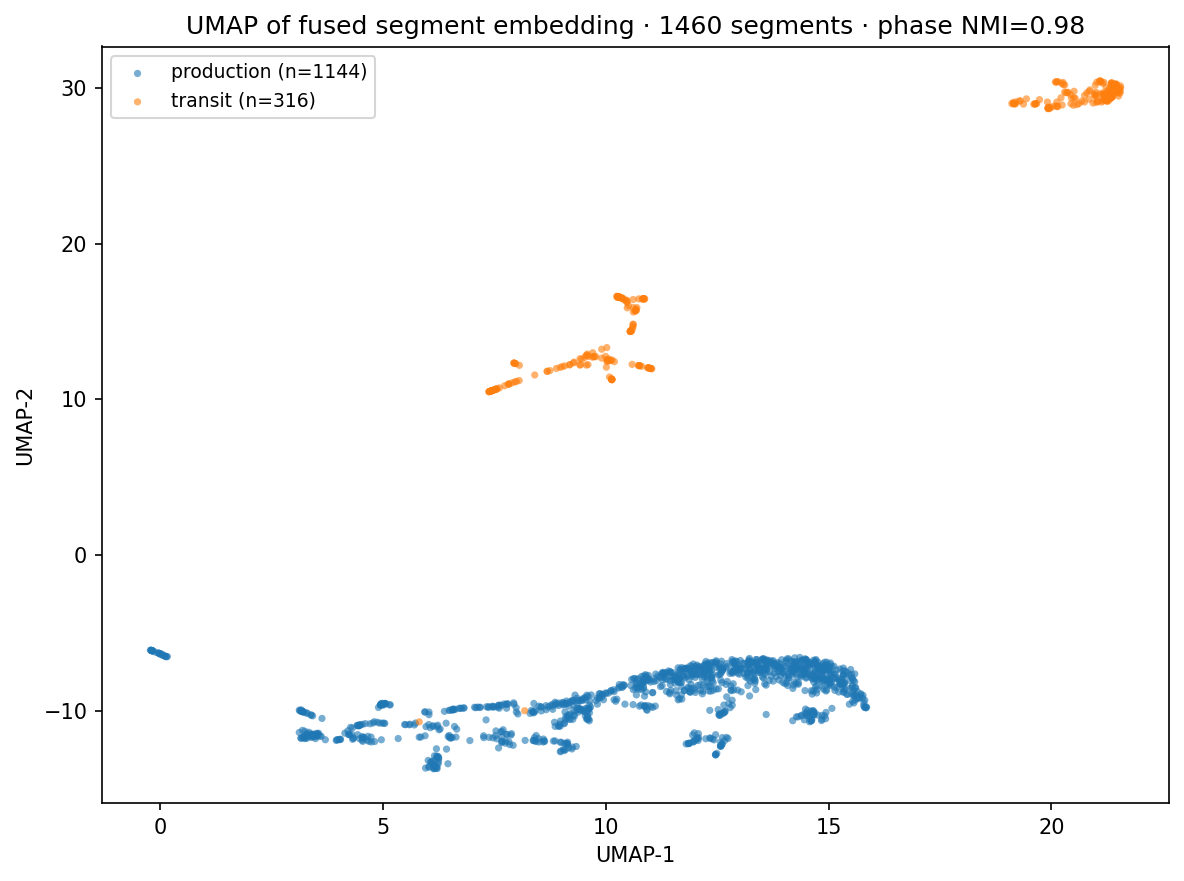
Comparing feature types (5 clips, 1,800 segments, 3 phases)
"Phase score" below is how well the discovered clusters agree with the phase label — 1.0 is perfect agreement, 0 is random.
| which features were used | phase score |
|---|---|
| motion only | 0.14 |
| scene only (DINOv2) | 0.77 |
| video only (V-JEPA-2) | 0.81 |
| motion + scene | 0.63 |
| motion + scene + video (the full pipeline) | 0.79 |
Three readings. First, motion alone is hopeless on this footage (0.14) — hand-pose dynamics aren't the discriminating signal here, scene context is. Second, V-JEPA-2 on its own is the strongest single feature, which matches what its authors argue: a video model trained for physical-world understanding is a good backbone for unsupervised activity discovery. Third, the full combination doesn't lose ground to V-JEPA-2 on phase agreement and produces visibly tighter clusters in the 2-D map above.
4 · What this doesn't do yet
- "Phase" is a coarse label. Production / transit / downtime / prep is a four-class label, not a fine-grained taxonomy. There's no ground truth at the per-activity level (e.g. "trowel a row" vs "carry a bucket"), so we can only check agreement with the coarse phase.
- Hand pose is partly fixed, not fully solved. The off-the-shelf hand tracker only fires on 3-7 % of frames. We added a second hand model (WiLoR [4]) anchored to the few frames where the first one succeeded, then propagated those detections forward and backward in time. Coverage on the five featured clips lifted to 21-47 %. Still well short of every-frame coverage on this gloved/fisheye footage.
- Camera motion isn't subtracted. Optical flow currently includes head motion, so what we call "wrist motion" is really "image-space hand motion." Stabilising for camera motion is a known follow-up.
- Tools aren't identified explicitly. Tasks that look visually similar at the wider scene level (e.g. trowelling vs spreading) could be separated by reading the held tool. The pieces to do that are plumbed in but not used in scoring yet.
- Number of clusters is data-dependent. On a longer or more varied dataset, the right number of clusters would change, and the method for choosing it would need to grow with the data.
References
- M. Oquab et al., "DINOv2: Learning Robust Visual Features without Supervision," Trans. Mach. Learn. Res., 2024.
- M. Assran et al., "V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning," arXiv preprint, 2025.
- C. Lugaresi et al., "MediaPipe: A Framework for Building Perception Pipelines," arXiv preprint arXiv:1906.08172, 2019.
- R. A. Potamias et al., "WiLoR: End-to-end 3D Hand Localization and Reconstruction in-the-wild," in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2025.
- Gemini Team, Google, "Gemini: A Family of Highly Capable Multimodal Models," arXiv preprint arXiv:2312.11805, 2023.